Yapay Zekâ Güvenliği Kariyerleri #3
Benchmarklar, FrontierMath, SWE-bench, ARC-AGI ve METR zaman ufku üzerinden yapay zekâ ilerlemesinin hızını inceliyoruz.
Serinin ilk iki yazısında yapay zekâdaki ilerlemenin tarihini ve mekaniğini konuştuk. İlk yazıda Turing ve Cahit Arf’tan başlayıp 2017’de transformatör mimarisinin bugünkü büyük dil modellerinin önünü nasıl açtığını anlattık. İkinci yazıda bu mimarinin devasa ölçekte uygulanmasının ne anlama geldiğine baktık: GPT-3’ün öngörülemeyen yetenekleri, ölçeklendirme kanunları, RLHF’in modelleri kullanılabilir hale getirmesi ve GPT-4 sıçraması.
Bu iki yazıda yapay zekâ sistemlerinin hızla gelişmesini sağlayan mekanizma ve inovasyonları anlattık. Şimdi bir adım geri çekilip şu soruyu soracağız: bu ilerleme gerçekten iddia edildiği kadar hızlı mı?
“Yapay zekâ son birkaç yılda muazzam ilerledi” artık banal bir gözlem. ChatGPT’nin ilk versiyonuyla bugünkü hali arasındaki farkı çoğumuz bizzat deneyimliyoruz. Yine de her yeni model çıktığında “şimdiye kadarki en gelişmiş” diye ilan ediliyor. Bunların ötesinde: Üstelik modeller artık sadece soru cevaplamıyor; modeller artık yalnızca metin üretmiyor; yazılım, analiz ve bilimsel araştırma tarafında uzun ve çok adımlı işleri giderek daha bağımsız biçimde yürütebiliyor.
Bu yazıyı yazıp, düzenlememiz, ve paylaşmamız arasında geçen kısa sürede Anthropic, Claude Fable 5 modelini duyurdu. Duyuruda aktarılan erken testlere ve Anthropic’in kendi değerlendirmelerine göre artık aylar sürebilecek bazı mühendislik işlerini günlere indiren, ilaç tasarım sürecinin bazı kısımlarını yaklaşık 10 kat hızlandıran modellerden söz ediyoruz.
Aynı zamanda Fable 5’in hangi model hattından geldiği önemli hale geliyor. Çünkü Fable 5, birkaç ay önce siber güvenlik kapasitesi nedeniyle genel kullanıma açılmayan Mythos Preview ile aynı temel modele sahip. Mythos hakkında daha ayrıntılı analiz için sistem kartı incelememizin birinci, ikinci ve üçüncü bölümlerine bakabilirsiniz.
Bu örnekler nitel olarak oldukça etkileyici. Ama modellerin etkileyici şeyler yapabiliyor olması, ilerlemenin boyutunu anlamamız için tek başına yeterli değil. Şirketlerin anlattığı kullanım örnekleri gerçek bir kapasite artışına işaret ediyor olabilir; aynı zamanda bu örneklerin pazarlama amaçlı seçilmiş olması da mümkün.
Bu yüzden modellerin ilerleme hızına dair yorum yapmadan önce şu soruyu cevaplamakta fayda var: bütün bu ilerleme gerçekten ölçülebilir mi?
Bu soruyu cevaplamaya çalışırken iki engelle karşılaşıyoruz.
Birincisi: öznel izlenimler objektif ölçüm niteliği taşımıyor. ChatGPT’nin verdiği bir cevap karşısında etkilenmiş olabiliriz, bir başka modelin basit bir soruda tökezlediğini görünce hayal kırıklığına uğramış olabiliriz. “Bu model çok akıllı” cümlesi bir his aktarır, bir bulgu sunmaz. Aynı model araştırma konusunda parlayıp tasarım konusunda tökezleyebilir. Tekil deneyimler yanıltıcı.
İkincisi: “daha iyi” demenin kendisi belirsiz. Bir model akıcı yazabilir ama matematikten anlamayabilir; başka bir model kod yazabilir ama günlük konuşmada yetersiz kalabilir. Bu fenomen, İngilizce literatürde “jagged frontier” olarak tabir ediliyor.
Yapay zeka araştırmacılarının bu iki problemi aşmak için “benchmark” adı verilen değerlendirmeler geliştiriyor ve kullanıyor. Her benchmark belirli bir beceri eksenini veya niteliği ölçüyor: kod yazma, matematik problemleri çözme, mantık yürütme, dil anlama, görsel işleme, mesleki bilgi. Her eksende modelin performansı sayısal bir skorla ifade ediliyor.
Önemli olan şu: tek bir benchmark tek bir eksen. Bir modelin “genel olarak iyi” olup olmadığını anlamak için birden çok benchmark’a bakmak gerekiyor. Birden çok benchmark, birden çok eksen demek. Birden çok model arası karşılaştırma da zaman içinde ilerlemenin takibi demek. Böylece “bu model akıllı mı” sorusundan “bu model şu eksende, şu tarihte, şu modelden ne kadar ileride” sorusuna geçebiliyoruz.
Ama benchmark’lar da mükemmel bir araç değil. Benchmarkların iki önemli kısıtlaması var.
Birincisi: “benchmaxxing”. Şirketler, modellerini yayınlarken benchmark skorlarını pazarlama aracı olarak kullanıyor. Bu da modellerin belirli testlerde yüksek skor almak için optimize edilmesi riskini doğuruyor. Tıpkı bir öğrencinin konuyu öğrenmek yerine sınav kalıplarını ezberlemesi gibi: skor yükselir ama altta yatan yetenek o kadar artmamış olabilir. O öğrenci farklı bir sınava girdiğinde ya da aynı konuyu farklı bir şekilde sorduğunuzda tökezleyebilir. Aynı şey modeller için de geçerli.
İkincisi, daha enteresan bir problem: satürasyon. Modeller o kadar hızlı gelişiyor ki bazı benchmark’lar ayırt edici olmaktan çıkıyor. Tüm modeller tavan skora yaklaştığında test artık modeller arasında ayrım yapamıyor. Bu noktada benchmark işlevini yitiriyor ve araştırmacılar daha zor testler tasarlamak zorunda kalıyor. Bu döngü yapay zekâ alanında sürekli tekrarlanan bir örüntü; birazdan somut örneklerini göreceğiz.
Benchmark güvenilirliğiyle ilgili daha yapısal sorunlar, ve çıkar çatışmaları da olabiliyor.1
Bu kısıtlamalara rağmen, benchmark’lar elimizdeki en iyi sistematik ölçüm aracı. Öznel izlenimleri sayılara dönüştürüyor, farklı modelleri karşılaştırılabilir kılıyor ve zaman içindeki ilerlemeyi takip edilebilir hale getiriyor. Mükemmel değiller, ama “hissettiriyor” dan çok daha güvenilirler.
Peki bu testlerde son birkaç yılda ne oldu?
Benchmarklar bize neler söylüyor?
Matematikteki İlerleme: GSM8K’dan Erdös Problemlerine
İnceleyeceğimiz ilk benchmark örneği, matematikten geliyor. 2021’de OpenAI, GSM8K adındaki benchmark’ı yayınlamıştı. Bu benchmark, ilk ve ortaokul düzeyinde 8500 civarı sayıda matematik problemlerinden oluşuyordu. Sorular kolaydı ancak çok adımlı akıl yürütme gerektiriyordu. O dönemin yapay zekâ modelleri için bu hâlâ zor bir görevdi. Hatta OpenAI’ın bu benchmark hakkında makalesi de basitliklerine rağmen mevcut yapay zekâ modellerinin bu sorularda çuvalladığından dem vuruyordu.
Günümüzden bakınca bu kulağa tarih öncesi devirler gibi geliyor. Artık GSM8K gibi benchmarklar yapay zekâ modelleri için fazla kolay. Bu da artık bu düzeydeki benchmarkların birer kıyas ölçütü olarak anlam kaybetmesine yol açıyor. Bu probleme “satürasyon problemi” adını veriyoruz: başta modeller arasında anlamlı bir kıyas yapan testler, modellerin tamamı tam puana yaklaşmaya başlayınca ayırt edici gücünü kaybediyor.
Benchmarklar satüre oldukça yeni benchmarklar geliştirmek gerekiyor. Mesela matematikte günümüzde hâlâ zor olan bir benchmark örneği olarak Epoch AI tarafından geliştirilmiş FrontierMath’i verebiliriz. Bu benchmark, profesyonel matematikçiler tarafından yazılmış, üst düzey (matematikçiler için bile!) ve özgün matematik problemlerinden oluşuyor. Bu soruların zorluk derecenizi kavramanız için şunu söyleyelim: Epoch AI’a göre bu matematik soruları, matematikçileri dahi saatlerce hatta günlerce uğraştıracak cinsten.
FrontierMath’in bize sunduğu tablo enteresan. 4. zorluk seviyesindeki sorulardaki (Tier 4) başarı oranı 2024’te neredeyse sıfırken 2025 sonunda %30’un üzerine çıktı. Bu hâlâ “yapay zekâ matematikçileri işsiz bıraktı” anlamına gelmiyor elbette. En gelişmiş modeller bile bu düzeydeki soruların çoğunu çözemiyor. Ama daha birkaç yıl önce ilköğretim düzeyindeki sorularda tökezleyen yapay zekânın bu hızlı ilerleyişi bir hayli şaşırtıcı.
Bunun da ötesinde, yapay zekânın matematikteki ilerlemesi sadece benchmark puanlarındaki artıştan ibaret de değil. 2025’te Uluslararası Matematik Olimpiyatlarında Google’ın Gemini Deep Think modeli altın madalya düzeyinde başarı sergiledi. Mayıs 2026’da ise OpenAI’a ait bir model, matematikçiler tarafından yaygın bir şekilde bilinmesine rağmen aksi ya da kendisi ispatlanamamış bir Erdös problemini bir karşı örnek bularak çürüttü. Bu da yapay zekânın matematiğe, bu yazının yazıldığı tarihe değin yaptığı, en büyük katkı.
Programlamadaki İlerleme
Matematik belki size nispeten soyut bir alan gibi görünmüş olabilir. Programlama muhtemelen size daha somut gelecektir: yapay zekâ modelleri gerçek yazılım hatalarını bulup düzeltebiliyor mu?
Bunu ölçmeyi amaçlayan benchmark’ların en önemlilerinden biri SWE-bench. SWE-Bench, Github’daki gerçek yazılım sorunlarından oluşuyor. Modelin bu sorunları çözecek yamalar üretmesi bekleniyor. Bu “şunu yapan bir fonksiyon yaz” tarzındaki testlerden çok daha gerçekçi bir performans değerlendirmesi sağlamayı amaçlıyor.
SWE-bench Verified ise bu benchmark’taki görevlerin yazılım uzmanları tarafından seçilmiş 500 örneklik daha temiz bir alt kümesinden oluşuyor. Benchmark’larda sık karşılaştığımızı söylediğimiz klasik döngüyle burada da karşılaşıyoruz: bu benchmark da maalesef satüre oldu ve OpenAI 2026 yılında artık raporlamayı bırakacağını duyurdu.
Bunun yarattığı boşluğu ise şu anlık SWE-Bench Pro dolduruyor. Daha gerçekçi, daha çeşitli, ve, en önemlisi de, daha zor yazılım görevlerini içeriyor. Şu anda liderlik koltuğu %64.3 ile Claude Opus 4.7 modelinde.
Bir de terminal kullanarak gerçek görevleri gerçekleştirme yeteneğini ölçmeyi amaçlayan Terminal-Bench 2.0 adlı benchmark var. Bu benchmark; yazılım mühendisliği, siber güvenlik, makine öğrenimi, ve veri bilimi gibi çeşitli alanlardan derlenmiş 89 görevden oluşuyor. GPT-5.5 gibi öncü yapay zekâ modelleri %80’lik eşiği aştı bile.
Benchmark skorlarının ötesinde: Gerçek dünyadan örnekler
Programlama benchmark’larındaki ilerlemeler dahi size hâlâ soyut geliyor olabilir ve yapay zekâ ilerlemesinin gerçek dünyadaki etkisini sorguluyor olabilirsiniz. Sonuçta, eğer değer üretmiyorlarsa, dünyaya fayda sağlamıyorlarsa yapay zekâ modellerinin aldığı skorlar bizi neden ilgilendirsin ki?
Bu soruya verilebilecek en güçlü cevaplardan biri AlphaFold. Proteinlerin üç boyutlu yapısını tahmin etmek, moleküler biyologların on yıllardır uğraştığı sinir bozucu derecede zor bir problemdi. Deney yaparak tahmin etmek hem pahalı hem de yavaştı. Google DeepMind’ın AlphaFold 2 modeli bu konuda büyük bir atılım yapmamızı sağladı. DeepMind CEO’su Demis Hassabis bu konudaki çalışmalarının sonucunda John Jumper’la beraber 2024 Nobel Kimya ödülüne layık görüldü.
Bu örnek önemli zira yapay zekânın artık sohbet robotlarından ibaret olmadığını gösteriyor. Bu modeller artık aynı zamanda bilim insanlarının işlerini kolaylaştıran bir bilimsel araç.
İkinci örnek, Japonya’dan geliyor ve bilimsel araştırma süreçlerini tamamen otomatize etmeyi amaçlıyor.
Sakana AI’ın AI Scientist-v2 sistemi, bilimsel araştırmanın hipotez üretme, deney tasarımı, deney sonuçlarının yorumlanması, verilerin görselleştirilmesi ve makale yazımı gibi adımlarının tamamını otomatize etmeye çalışan bir sistem olarak tanıtıldı. Sakana AI araştırmacıları, bu sistem tarafından yazılmış çalışmaları ICLR 2025 çalıştay sürecine soktuklarını ve bu çalışmalardan birinin kabul edildiğini söylüyor.
Video ve resim üreten yapay zekâ modellerinde de hızlı bir ilerleme görünüyor ki buradaki ilerleme gözle görülebilir olduğu için kavramak daha kolay. Aynı komuta bir yıldan az süreyle yayınlanmış iki modelin verdiği çıktıyı karşılaştırın:


Soldaki resmi yapan model, Google DeepMind’a ait Imagen 4 Ultra modeli. Sağdakini ise OpenAI’a ait GPT Image 2 modeli yaptı.
AGI’a yaklaşıyor muyuz?
Bu soruyu ele alırken dikkatli olmamız gerektiği kanısındayız. Bir modelin spesifik bir görev kümesinde “insanüstü” derecede başarılı olması, onun yapay genel zekâ yani AGI olduğunu garantilemez. Zaten bu yazının asıl amacı da AGI’ın gelmek üzere olup olmadığını tartışmak değil.
Ama en azından şunu gözlemlediğimizi size göstermek: modellerin yetenekleri sadece bir iki alanda değil tüm alanlarda oldukça hızlı bir derecede artıyor. Bunun yanı sıra doğrudan genel zekâyı ölçmeyi hedefleyen benchmark’lar var. Bunlardan en önemlisi hiç şüphesiz ARC-AGI.
François Chollet’nin ve ekibinin geliştirdiği ARC-AGI benchmarkını enteresan kılan şey de bu. Eğer biraz psikoloji arkaplanınız varsa size şöyle açıklayabiliriz: SWE-Bench gibi benchmarklar daha çok kristalize zekâyı ölçüyorsa, ARC-AGI da akışkan zekâyı ölçmeyi amaçlıyor.
ARC-AGI benchmarkları, modellerin daha önce karşılaşmamış olduğu IQ-testi benzeri bulmacaları kullanıyor. Bu bulmacalarda modelin kuralı az sayıda örnekten tahmin edip yeni örneğe uygulaması gerekiyor.
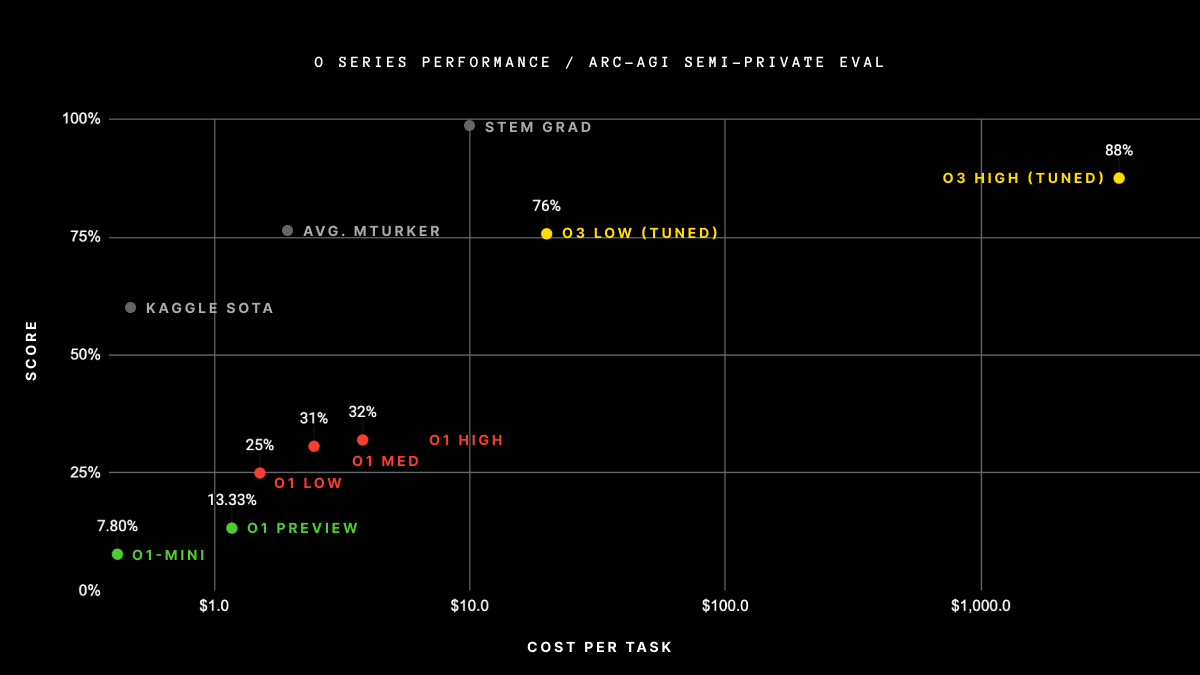
2024’ün sonunda OpenAI o3-preview adını verdiği sistemin (bu yayınladıkları o3 modeliyle aynı olmayan, çok daha maliyetli olan bir sistem) ARC-AGI-1’den yüksek hesaplama modunda %87,5 aldığını duyurdu. Bu, yapay zekâ dünyasında şok etkisi yaratan bir gelişmeydi.
Fakat, bu gelişmenin ardından çıta hemen yükseldi. ARC-AGI ekibi, ARC-AGI-2’yi yayınladı ve öncü modellerin bu benchmark’ta %5’ten az aldıklarını belirtti. 2025 sonunda ise en yüksek skor %24’e ulaştı.
Öngörüleri Test Etmek
Benchmark’ları değerli kılan şey sadece belli bir tarihte yayında olan modeller arasında mukayese yapabilmek değil. Benchmarkların bize sunduğu başka bir artı daha var: yapay zekânın ilerleyiş hızı hakkındaki öngörülerimizi test edebilmek.
Sözgelimi, biri eğer “2025 ortasında SWE-Bench Verified’da %85 skoru geçilecek” gibi bir tahmin yaptıysa bunu 2025 ortasına geldiğimizde test edebiliriz. Bu sayede gerçekten abartılmış bir balon olup olmadığını anlayabiliriz.
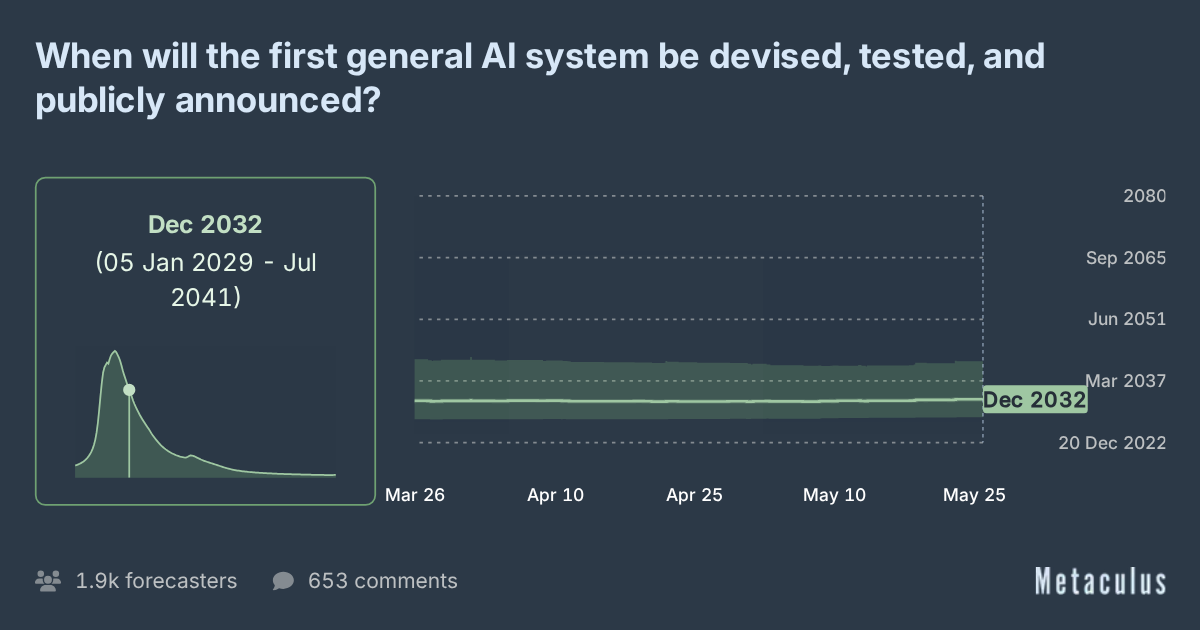
Bu çerçevede AI 2027 gibi yapay zekânın hızı hakkındaki en iddialı projeksiyonlardan birinin geriye dönük değerlendirmesine bakabiliriz. AI Futures Project, bu değerlendirmeyi yaptığında gerçek hızın bu senaryonun öngördüğü hızın %65’i civarında olduğunu, nicel tahminlerin ise isabetli olduğunu söylemiş.
Bunu “AI hızlı ilerlemiyor” olarak yorumlamadan önce AI 2027’nin en agresif senaryolardan biri olduğunu akılda tutmakta yarar var. Mesela Metaculus’un medyan tahmini çok daha geç: 2032.
AGI’a 2027’de ulaşacağımızı iddia eden bir senaryonun %65’i hızında ilerliyorsak eğer, bu hâlâ çok hızlı ilerlediğimiz anlamına geliyor. Bu, insanlık tarihindeki en büyük teknolojik devrimlerden birine şahit ediyoruz demek.
Özellikle işlerin “ajan AI” kısmında bunu net bir şekilde seçebiliyoruz. Artık modeller sohbet robotu tarzı diyalogla çalışıp bizi yönlendirmekten çok kendileri bilgisayar komutları çalıştırıp işleri halledebiliyor.
Üstelik giderek daha uzun işleri hallediyor. Buradaki kilit metrik METR’ın sonuçları. METR’a ait “Task-completion Time Horizon” adlı benchmark şunu ölçmeye çalışıyor: Bir yapay zekâ ajanı alanında uzman bir insanın belli bir süre içerisinde tamamlayabildiği görevlerde ne kadar güvenilir. Başka bir deyişle denemelerin kaçında başarılı oluyor?
Mesela buradaki “%50 başarı oranı zaman ufku”, modelin X dakika süren görevleri yarı yarıya başarı oranında tamamlayabilmesi demek.
METR’ın 2025’te yayınladığı bir çalışmada ilginç bir sonuç dikkat çekiyordu: 2019’dan 2025’e kadar olan süre içerisinde bu zaman ufku her 7 ayda bir ikiye katlanıyordu.
Bu eğilim hâlâ devam ediyor, hatta hızlandı bile: 2023 öncesi modellerde 196 gün olan ikiye katlanma süresi 2023 sonrası modellerde 131 güne indi. Yapay zekâ yalnızca hızlı ilerlemiyor, ayrıca ilerleme hızı da artıyor.
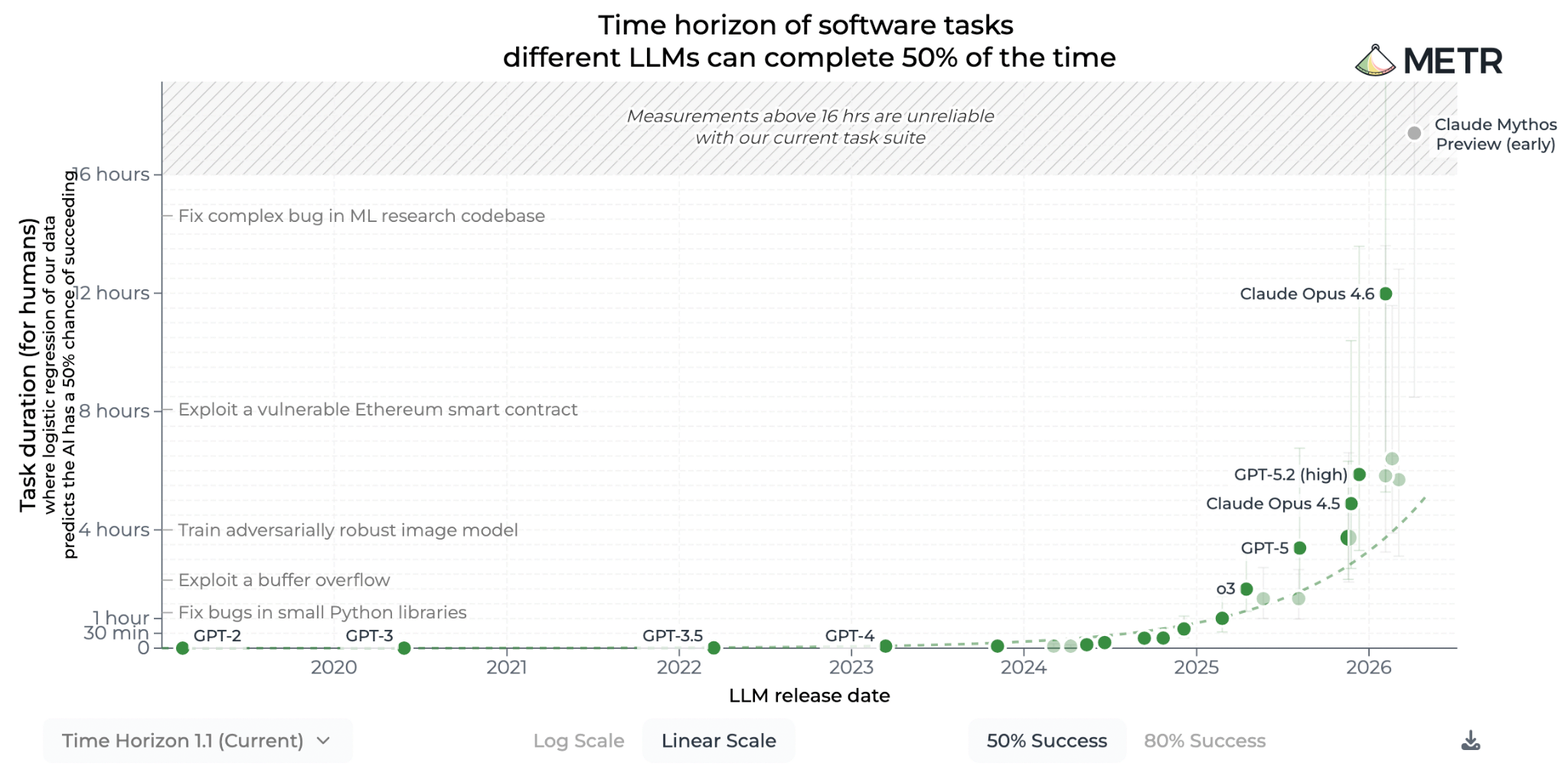
Mayıs 2026 itibarıyla 16 saatlik çıta Claude Mythos Preview tarafından aşıldı; ve evet bu test de satüre edildi. METR gibi kuruluşlar artık yapay zekâ modellerinin ilerleme hızına ayak uydurmakta zorluk çekiyor.
METR’ın kurucusu Beth Barnes şu uyarıyı yapıyor: “Bence, aklı başında herhangi bir medeniyet yapay zekâ konusunda işleri çok daha yavaştan alırdı ve çok daha dikkatlice yürütürdü. Gelişmiş yapay zekânın avantajlarını biraz daha hızlı elde etmenin faydaları, telafisi imkânsız hatalar yapma riskine kıyasla küçük ve daha yavaş ilerleyerek bu riskleri azaltabiliriz.”
Sonuç
Yazının başında sorduğumuz soru basitti: yapay zekâdaki ilerleme gerçekten iddia edildiği kadar hızlı mı, yoksa ortada abartılmış bir tablo mu var?
Benchmark’lar bu soruyu “hissediyor musun"dan “ölçebiliyor musun"a taşıdı. Mükemmel araçlar değiller; satüre oluyorlar, benchmaxxing’e açıklar. Ve bir noktayı netleştirmekte fayda var: ciddi bir ilerleme olması, yapay zekâ şirketlerinin veya bu işten para kazanan insanların bazı şeyleri abartmadığı anlamına gelmiyor. Abartı var, çıkar çatışması var, ve benchmark’ların kendisi bile bu çatışmalardan muaf değil. Ama benchmark’ların bize verdiği şey yine de değerli: farklı modelleri aynı eksenlerde, zaman içinde karşılaştırabilmek.
Bu karşılaştırmayı yaptığımızda gördüğümüz tablo oldukça net ve aslında pek çok insanın gündelik hayatta ya da iş hayatında hissettiği şeyi teyit ediyor. Yukarıda gördüğümüz gibi, ilkokul düzeyinde matematik sorularında tökezleyen modeller birkaç yıl içinde matematikçilerin on yıllardır çözemediği problemlerin altından kalkabilir. Gerçek yazılım hatalarını çözme oranları sıfırdan %80’lerin üstüne çıktı. Tıbbi teşhiste uzman doktorlar seviyesinde performans gösterdi; hukuk sınavlarında dört ayda geçme barajını aştı. Protein katlanması gibi on yıllardır çözülemeyen bilimsel problemlerde çığır açıldı, Nobel ödülüne giden araştırmalara katkıda bulunuldu.
Ve burada dikkat çekici olan şu: bu ilerleme tek bir göreve özelleşmiş sistemlerden gelmiyor. Satranç veya Go’da insanları yenen modeller yalnızca satranç veya Go oynuyordu. Bugün aynı model hem baro sınavını geçiyor, hem doktora düzeyinde matematik çözüyor, hem gerçek yazılım hatalarını buluyor, hem de IQ testi benzeri soyut bulmacalarda sıçrama yapıyor. Tek bir alanda dar bir sıçrama değil, geniş bir yelpazede eşzamanlı bir tırmanış.
Bunların çoğunu zaten hissediyorsunuz. ChatGPT’nin bugünkü versiyonuyla bir yıl önceki versiyonu arasındaki farkı, onu düzenli kullanan herkes fark ediyor. Benchmark’ların yaptığı şey bu hissi doğrulamak ya da düzeltmek: evet, ilerleme gerçek, ve hızlı.
Açık kalan iki soru var. Birincisi: bu hız neden bu kadar düzenli? Benchmark’lardaki ilerleme rastgele sıçramalar gibi değil, düzgün bir eğri izliyor. Önceki yazıda bahsettiğimiz ölçeklendirme dinamikleri bunun cevabının bir parçası olabilir. İkincisi: önümüzdeki yıllarda bu ivmeden ne bekleyebiliriz?
2025 başında, Epoch AI’ın geliştirdiği FrontierMath benchmark’ının OpenAI tarafından gizlice finanse edildiği ve OpenAI’ın veri setine ayrıcalıklı erişim sahibi olduğu ortaya çıktı. Benchmark’a katkıda bulunan matematikçilerin çoğu bu düzenlemeden habersizdi. Yani benchmark’ların güvenilirliği sadece teknik bir mesele değil, kimin finanse ettiği, kimin eriştiği ve bu bilginin ne zaman açıklandığı da önemli. ↩︎