In the first two articles of the series, we discussed the history and mechanics of progress in artificial intelligence. In the first article, starting from Turing and Cahit Arf, we explained how the transformer architecture paved the way for today’s large language models in 2017. In the second article, we looked at what applying this architecture on a massive scale means: GPT-3’s unpredictable capabilities, scaling laws, RLHF making models usable, and the GPT-4 leap.
In these two articles, we explained the mechanisms and innovations that enabled the rapid development of AI systems. Now, we will take a step back and ask this question: is this progress really as fast as claimed?
“Artificial intelligence has made tremendous progress in the last few years” is now a banal observation. Most of us personally experience the difference between the first version of ChatGPT and its current state. Yet, every time a new model is released, it is declared “the most advanced yet.” Beyond this: Moreover, models no longer just answer questions; models no longer just generate text; they can increasingly independently execute long and multi-step tasks in software, analysis, and scientific research.
In the short time between writing, editing, and sharing this article, Anthropic announced the Claude Fable 5 model. According to the early tests shared in the announcement and Anthropic’s own evaluations, we are now talking about models that reduce some engineering tasks that could take months down to days, and speed up certain parts of the drug design process by about 10 times.
At the same time, which model line Fable 5 comes from becomes important. Because Fable 5 shares the same base model as Mythos Preview, which was not released for general use a few months ago due to its cybersecurity capabilities. For a more detailed analysis of Mythos, you can check out the first, second, and third parts of our system card review.
These examples are qualitatively quite impressive. But the fact that models can do impressive things is not enough on its own for us to understand the extent of the progress. The use cases described by companies might indicate a real increase in capacity; at the same time, it is also possible that these examples were cherry-picked for marketing purposes.
Therefore, before commenting on the pace of progress of the models, it is useful to answer this question: is all this progress truly measurable?
We encounter two obstacles while trying to answer this question.
First: subjective impressions do not constitute objective measurements. We might be impressed by an answer given by ChatGPT, or we might be disappointed seeing another model stumble on a simple question. The sentence “This model is very smart” conveys a feeling, it does not present a finding. The same model might shine in research and stumble in design. Singular experiences are misleading.
Second: saying “better” is inherently vague. A model might write fluently but not understand math; another model might write code but fall short in everyday conversation. This phenomenon is referred to as the “jagged frontier” in English literature.
AI researchers develop and use evaluations called “benchmarks” to overcome these two problems. Each benchmark measures a specific skill axis or attribute: writing code, solving math problems, reasoning, language understanding, visual processing, professional knowledge. On each axis, the model’s performance is expressed with a numerical score.
The important thing is this: a single benchmark is a single axis. To understand whether a model is “generally good,” one needs to look at multiple benchmarks. Multiple benchmarks mean multiple axes. Comparing multiple models also means tracking progress over time. Thus, we can move from the question “is this model smart?” to “how far ahead is this model compared to that model, on this axis, at this date?”
But benchmarks are not a perfect tool either. Benchmarks have two major limitations.
First: “benchmaxxing”. Companies use benchmark scores as a marketing tool when releasing their models. This creates the risk of models being optimized to get high scores on specific tests. Just like a student memorizing exam patterns instead of learning the subject: the score goes up, but the underlying ability might not have increased as much. When that student takes a different exam or when you ask about the same subject in a different way, they might stumble. The same applies to models.
Second, a more interesting problem: saturation. Models are developing so fast that some benchmarks cease to be distinguishing. When all models approach the ceiling score, the test can no longer differentiate between models. At this point, the benchmark loses its function, and researchers are forced to design harder tests. This cycle is a constantly repeating pattern in the field of AI; we will see concrete examples of it shortly.
There can also be more structural problems and conflicts of interest regarding benchmark reliability.1
Despite these limitations, benchmarks are the best systematic measurement tool we have. They turn subjective impressions into numbers, make different models comparable, and make progress over time trackable. They are not perfect, but they are much more reliable than “it feels like.”
So what has happened in these tests over the last few years?
What do benchmarks tell us?
Progress in Math: From GSM8K to Erdős Problems
The first benchmark example we will examine comes from math. In 2021, OpenAI published a benchmark called GSM8K. This benchmark consisted of around 8,500 math problems at the elementary and middle school level. The questions were easy but required multi-step reasoning. For the AI models of that era, this was still a difficult task. In fact, OpenAI’s paper on this benchmark also lamented that despite their simplicity, existing AI models failed miserably at these questions.
Looking back from today, this sounds like prehistoric times. Now, benchmarks like GSM8K are too easy for AI models. This leads to benchmarks at this level losing their meaning as a standard of comparison. We call this problem the “saturation problem”: tests that initially make a meaningful comparison between models lose their distinguishing power when all models start approaching a perfect score.
As benchmarks become saturated, new benchmarks need to be developed. For example, we can give FrontierMath, developed by Epoch AI, as an example of a benchmark that is still difficult in math today. This benchmark consists of high-level (even for mathematicians!) and original math problems written by professional mathematicians. To help you grasp the difficulty level of these questions, let us say this: according to Epoch AI, these math questions are the kind that would take even mathematicians hours or even days to solve.
The picture FrontierMath presents to us is interesting. While the success rate on level 4 difficulty questions (Tier 4) was almost zero in 2024, it rose to over 30% by the end of 2025. This still doesn’t mean “AI has put mathematicians out of work,” of course. Even the most advanced models cannot solve most of the questions at this level. But this rapid progress of AI, which stumbled on elementary school-level questions just a few years ago, is quite astonishing.
Beyond this, AI’s progress in math is not just about the increase in benchmark scores. In 2025, Google’s Gemini Deep Think model achieved gold-medal-level success at the International Mathematical Olympiad. And in May 2026, a model belonging to OpenAI disproved an Erdős problem that was widely known by mathematicians but remained unproven or undisproved, by finding a counterexample. This is the greatest contribution AI has made to mathematics up to the date this article was written.
Progress in Programming
Math might have seemed like a relatively abstract field to you. Programming will probably feel more concrete: can AI models find and fix real software bugs?
One of the most important benchmarks aiming to measure this is SWE-bench. SWE-bench consists of real software issues on GitHub. The model is expected to generate patches that will solve these issues. This aims to provide a much more realistic performance evaluation than “write a function that does this” style tests.
SWE-bench Verified, on the other hand, consists of a cleaner subset of 500 examples of tasks in this benchmark, selected by software experts. We encounter the classic cycle here too, which we said we frequently encounter in benchmarks: unfortunately, this benchmark also became saturated, and OpenAI announced that it would stop reporting it in 2026.
The gap created by this is currently being filled by SWE-Bench Pro. It includes more realistic, more diverse, and, most importantly, harder software tasks. Currently, the leadership seat belongs to the Claude Opus 4.7 model with 64.3%.
There is also a benchmark called Terminal-Bench 2.0, which aims to measure the ability to perform real tasks using a terminal. This benchmark consists of 89 tasks compiled from various fields such as software engineering, cybersecurity, machine learning, and data science. Leading AI models like GPT-5.5 have already crossed the 80% threshold.
Beyond benchmark scores: Real-world examples
Even the progress in programming benchmarks might still seem abstract to you, and you might be questioning the real-world impact of AI progress. After all, if they are not creating value, if they are not benefiting the world, why should we care about the scores AI models get?
One of the strongest answers that can be given to this question is AlphaFold. Predicting the three-dimensional structure of proteins was a frustratingly difficult problem that molecular biologists had been struggling with for decades. Predicting it by conducting experiments was both expensive and slow. Google DeepMind’s AlphaFold 2 model enabled us to make a major breakthrough in this regard. As a result of his work on this subject, DeepMind CEO Demis Hassabis was awarded the 2024 Nobel Prize in Chemistry along with John Jumper.
This example is important because it shows that AI is no longer just about chatbots. These models are now also a scientific tool that makes the work of scientists easier.
The second example comes from Japan and aims to fully automate scientific research processes.
Sakana AI’s AI Scientist-v2 system was introduced as a system attempting to automate all steps of scientific research, such as hypothesis generation, experimental design, interpretation of experimental results, data visualization, and paper writing. Sakana AI researchers say they submitted papers written by this system to the ICLR 2025 workshop process and that one of these papers was accepted.
There is also rapid progress seen in AI models that generate video and images, and since the progress here is visible, it is easier to grasp. Compare the output given by two models released less than a year apart to the same prompt:


Are we approaching AGI?
We believe we need to be careful when addressing this question. A model being “superhumanly” successful in a specific set of tasks does not guarantee that it is artificial general intelligence, or AGI. Besides, the main purpose of this article is not to discuss whether AGI is about to arrive.
But it is at least to show you what we are observing: the capabilities of models are increasing at a very rapid rate, not just in one or two areas, but in all areas. In addition to this, there are benchmarks that directly aim to measure general intelligence. The most important of these is undoubtedly ARC-AGI.
This is what makes the ARC-AGI benchmark developed by François Chollet and his team interesting. If you have a bit of a psychology background, we can explain it to you like this: while benchmarks like SWE-Bench mostly measure crystallized intelligence, ARC-AGI aims to measure fluid intelligence.
ARC-AGI benchmarks use IQ-test-like puzzles that the models have not encountered before. In these puzzles, the model needs to infer the rule from a small number of examples and apply it to a new example.
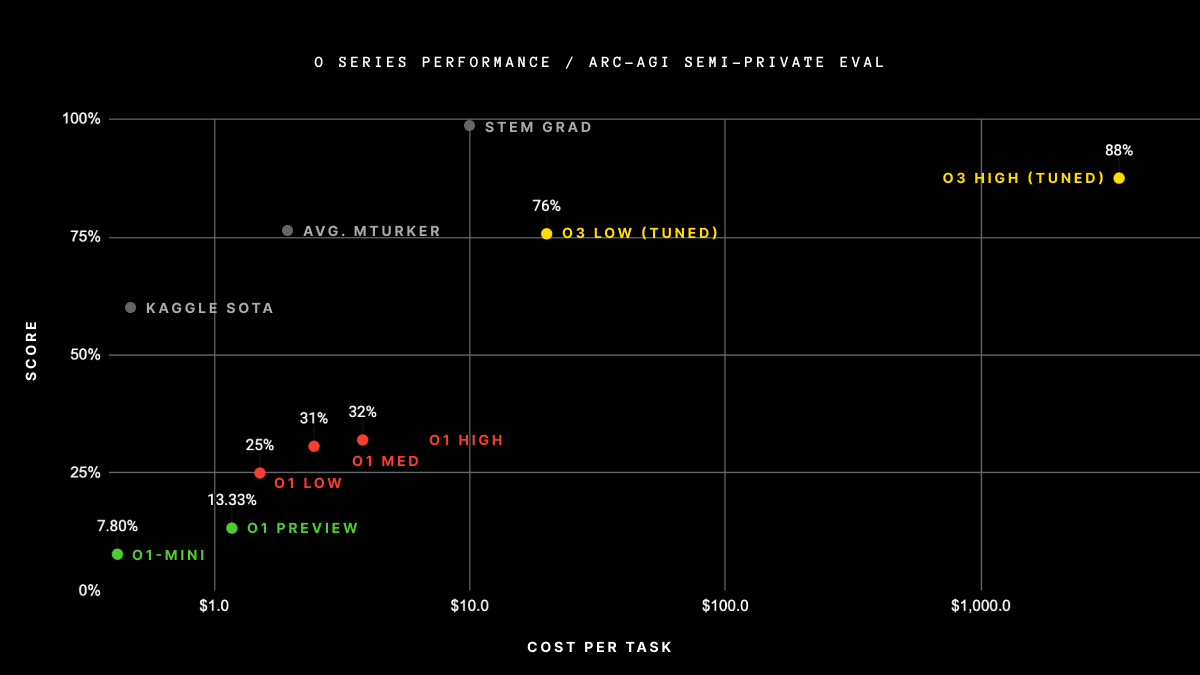
At the end of 2024, OpenAI announced that the system they called o3-preview (a much more costly system that is not the same as the o3 model they released) scored 87.5% on ARC-AGI-1 in high compute mode. This was a development that created a shockwave in the AI world.
However, following this development, the bar was immediately raised. The ARC-AGI team released ARC-AGI-2 and stated that frontier models scored less than 5% on this benchmark. By the end of 2025, the highest score reached 24%.
Testing Predictions
What makes benchmarks valuable is not just being able to make comparisons between models available on a certain date. There is another plus that benchmarks offer us: being able to test our predictions about the pace of AI’s progress.
For instance, if someone made a prediction like “a score of 85% will be surpassed on SWE-Bench Verified by mid-2025,” we can test this when we reach mid-2025. This way, we can understand whether it is truly an exaggerated bubble.
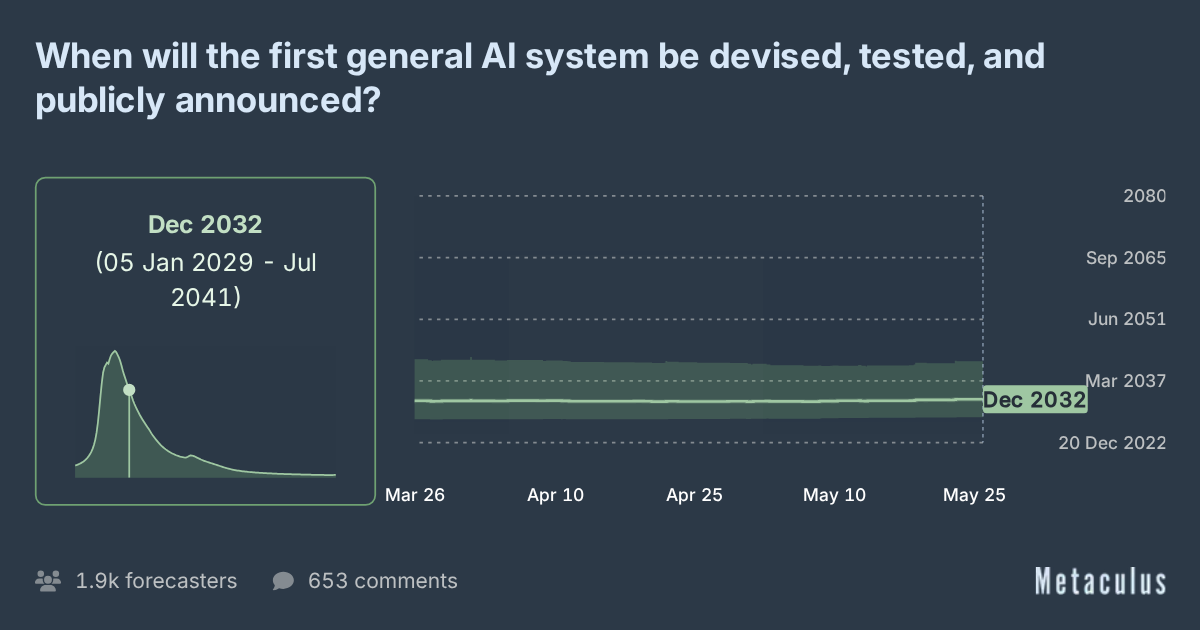
In this context, we can look at a retrospective evaluation of one of the most ambitious projections about the speed of AI, such as AI 2027. When the AI Futures Project made this evaluation, they stated that the actual speed was around 65% of the speed predicted by this scenario, and that the quantitative predictions were accurate.
Before interpreting this as “AI is not progressing fast,” it is useful to keep in mind that AI 2027 is one of the most aggressive scenarios. For example, Metaculus’s median prediction is much later: 2032.
If we are progressing at 65% of the speed of a scenario that claims we will reach AGI in 2027, this means we are still progressing very fast. This means we are witnessing one of the greatest technological revolutions in human history.
We can clearly distinguish this especially in the “agentic AI” part of things. Now, rather than working with chatbot-style dialogue and guiding us, models can run computer commands and get things done themselves.
Moreover, they are handling increasingly longer tasks. The key metric here is METR’s results. METR’s benchmark called “Task-completion Time Horizon” tries to measure this: How reliable is an AI agent in tasks that a human expert in the field can complete within a certain period of time? In other words, in how many of the attempts is it successful?
For example, the “50% success rate time horizon” here means that the model can complete tasks that take X minutes with a half-and-half success rate.
An interesting result stood out in a study published by METR in 2025: between 2019 and 2025, this time horizon was doubling every 7 months.
This trend is still continuing, and has even accelerated: the doubling time, which was 196 days for pre-2023 models, dropped to 131 days for post-2023 models. AI is not only progressing fast, but its rate of progress is also increasing.
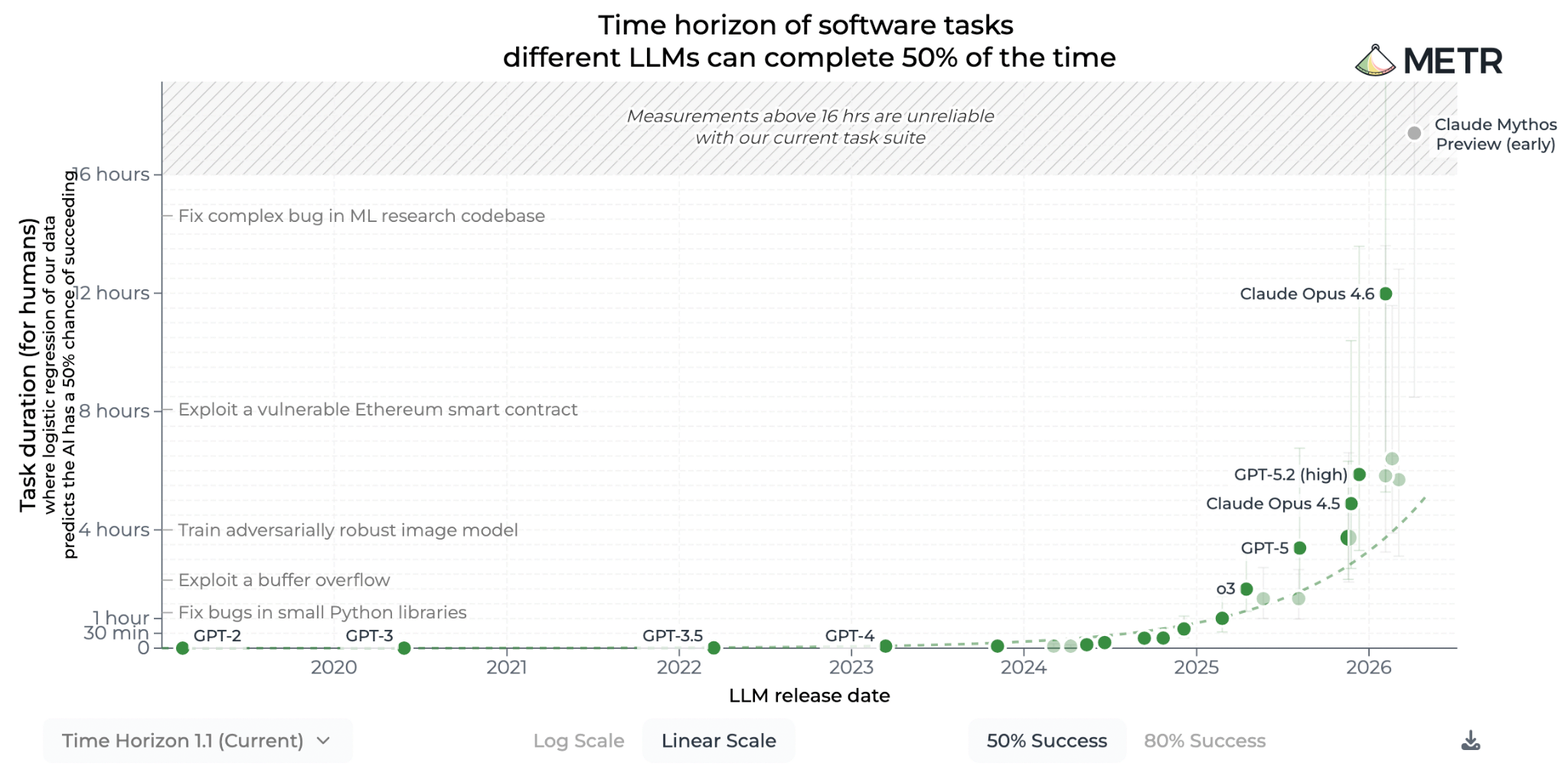
As of May 2026, the 16-hour bar was surpassed by Claude Mythos Preview; and yes, this test was also saturated. Organizations like METR are now struggling to keep up with the pace of progress of AI models.
METR’s founder Beth Barnes gives this warning: “I think any sane civilization would take things much slower and proceed much more carefully with AI. The benefits of getting the advantages of advanced AI a little faster are small compared to the risk of making irreversible mistakes, and we can mitigate these risks by moving slower.”
Conclusion
The question we asked at the beginning of the article was simple: is the progress in AI really as fast as claimed, or is there an exaggerated picture?
Benchmarks have moved this question from “do you feel it” to “can you measure it”. They are not perfect tools; they get saturated, they are open to benchmaxxing. And it is worth clarifying one point: the fact that there is serious progress does not mean that AI companies or people making money from this business are not exaggerating some things. There is hype, there are conflicts of interest, and even the benchmarks themselves are not exempt from these conflicts. But what benchmarks give us is still valuable: being able to compare different models on the same axes, over time.
When we make this comparison, the picture we see is quite clear and actually confirms what many people feel in their daily or professional lives. As we saw above, models that stumbled on elementary school-level math questions can, within a few years, tackle problems that mathematicians haven’t been able to solve for decades. Their rates of solving real software bugs went from zero to over 80%. They performed at the level of expert doctors in medical diagnosis; they passed the passing threshold in law exams in four months. Breakthroughs were made in scientific problems that couldn’t be solved for decades, like protein folding, contributing to research that led to a Nobel prize.
And what is remarkable here is this: this progress is not coming from systems specialized in a single task. Models that beat humans in chess or Go only played chess or Go. Today, the same model passes the bar exam, solves PhD-level math, finds real software bugs, and makes leaps in abstract puzzles similar to IQ tests. It’s not a narrow leap in a single field, but a simultaneous climb across a wide spectrum.
You already feel most of this. Anyone who uses it regularly notices the difference between today’s version of ChatGPT and the version from a year ago. What benchmarks do is validate or correct this feeling: yes, the progress is real, and it is fast.
There are two open questions. First: why is this pace so regular? The progress in benchmarks is not like random jumps, it follows a smooth curve. The scaling dynamics we mentioned in the previous article might be part of the answer to this. Second: what can we expect from this momentum in the coming years?
In early 2025, it was revealed that the FrontierMath benchmark developed by Epoch AI was secretly funded by OpenAI and that OpenAI had privileged access to the dataset. Most of the mathematicians who contributed to the benchmark were unaware of this arrangement. So the reliability of benchmarks is not just a technical issue; who funds them, who has access, and when this information is disclosed is also important. ↩︎